面試心得–GoFreight 聖學科技
2021/08/26~2021/09/16【Backend Web Developer / Software Developer】未錄取
職缺介紹#
請見 Yourator 職缺連結—Backend Web Developer / Software Developer - GoFreight找到熱血沸騰的新創工作open_in_new。PTT 也有相關面試心得文可供參考-[心得] 面試-Seasalt/GoFreight/Line/Google/Arcopen_in_new。
第一輪線上技術測驗#
總共 5 題 HackerRank 題目,時間限制 120 分鐘。
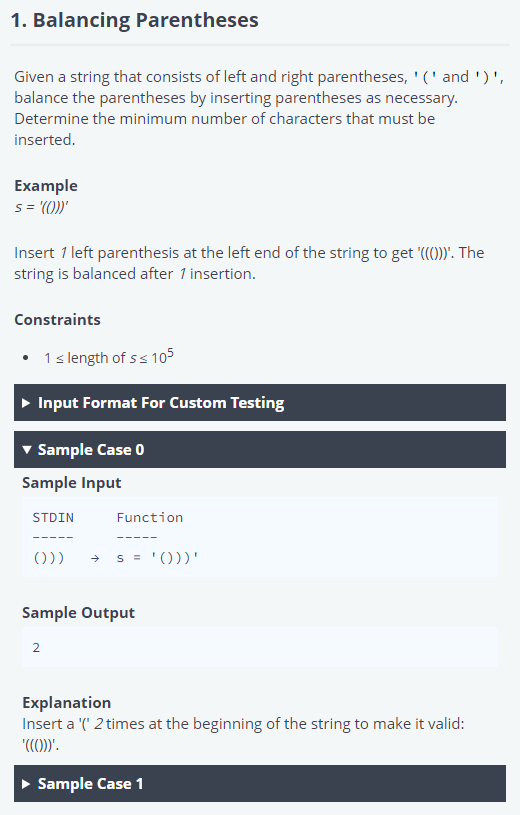
1. Balancing Parentheses#
Given a string that consists of left and right parentheses, '(' and ')', balance the parentheses by inserting parentheses as necessary. Determine the minimum number of characters that must be inserted.
Example
s = '(()))'
Insert 1 left parenthesis at the left end of the string to get '((()))'. The string is balanced after 1 insertion.
Constraints
- length of
2. No Pairs Allowed#
For each word in a list of words, if any two adjacent characters are equal, change one of them. Determine the minimum number of substitutions so the final string contains no adjacent equal characters.
Example
words = ['add', 'boook', 'break']
- 'add': change one d (1 change)
- 'boook': change the middle o (1 change)
- 'break': no changes are necessary (0 changes)
The return array is [1,1,0].
Function Description
Complete the function minimalOperations in the editor below.
minimalOperations has the following parameter(s):
- string words[n]: an array of strings
Returns:
- int[n]: each element is the minimum substitutions for words[i]
Constraints
- length of words[i]
- Each character of words[i] is in the range ascii[a-z].
3. Fun with Anagrams#
Two strings are anagrams if they are permutations of each other. In other words, both strings have the same size and the same characters. For example, "aaagmnrs" is an anagram of "anagrams". Given an array of strings, remove each string that is an anagram of an earlier string, then return the remaining array in sorted order.
Example
str = ['code', 'doce', 'ecod', 'framer', 'frame']
- "code" and "doce" are anagrams. Remove "doce" from the array and keep the first occurrence "code" in the array.
- "code" and "ecod" are anagrams. Remove "ecod" from the array and keep the first occurrence "code" in the array.
- "code" and "framer" are not anagrams. Keep both strings in the array.
- "framer" and "frame" are not anagrams due to the extra 'r' in 'framer'. Keep both strings in the array.
- Order the remaining strings in ascending order: ["code","frame","framer"].
Function Description
Complete the function funWithAnagrams in the editor below.
funWithAnagrams has the following parameters:
- string text[n]: an array of strings
Returns:
- string[m]: an array of the remaining strings in ascending alphabetical order.
Constraints
- length of text[i]
- Each string text[i] is made up of characters in the range ascii[a-z].
4. Counting Pairs#
Given an integer k and a list of integers, count the number of distinct valid pairs of integers (a, b) in the list for which a + k = b. Two pairs of integers (a, b) and (c,d) are considered distinct if at least one element of (a, b) does not also belong to (c,d). Note that the elements in a pair might be the same element in the array. An instance of this is below where k = 0.
Example
n = 4
numbers = [1, 1, 1, 2]
k = 1
This array has three different valid pairs: (1, 1) and (1, 2) and (2, 2). For k = 1, there is only 1 valid pair which satisfies a + k = b: the pair (a, b) = (1, 2).
n = 2
numbers = [1, 2]
k = 0
There are three valid pairs: (1, 1), (2, 2) and (1,2). For k = 0, two valid pairs satisfy a + k = b: 1 + 0 = 1 and 2 + 0 = 2.
Function Description
Complete the function countPairs in the editor below.
countPairs has the following parameter(s):
- int numbers[n]: array of integers
- int k: target difference
Returns
- int: number of valid (a, b) pairs in the numbers array that have a difference of k
Constraints
- numbers[i] , where
5. Scatter-Palindrome#
A palindrome is a string which reads the same forward and backwards, for example, tacocat and mom. A string is a scatter-palindrome if its letters can be rearranged to form a palindrome. Given an array consisting of n strings, for each string, determine how many of its substrings are scatter-palindromes. A substring is a contiguous range of characters within the string.
Example
strToEvaluate = ['aabb']
The scatter-palindromes are a, aa, aab, aabb, a, abb, b, bb, b. There are 9 substrings that are scatter-palindromes.
Function Description
Complete the scatterPalindrome function in the editor below.
scatterPalindrome has one parameter:
- string strToEvaluate[n]: the n strings to be evaluated
Returns
- int[n]: each element i represents the number of substrings of strToEvaluate[i] which are scatter-palindromes.
Constraints
- size of strToEvaluate[i]
- all characters of strToEvaluate[i] ascii[a-z]
第二輪線上技術測驗#
此關簡直是惡夢,要經歷 4 位面試官,總共 5 大題,歷經 4 個多小時才度過整個車輪戰,還被迫破例為了面試而請假,不過題目品質相較其他公司確實精緻許多,可以感受到該公司在挑選人才上的用心。
實作 Heap(面試官:Gary)#
車輪戰第一輪直接被要求實作 Heap,實作過程是允許查詢資料的,但不能直接查詢答案。一開始先被詢問 Heap 的特性,但我太久沒複習已經失憶了,只好當場 Google 一番;問完特性後就被要求實作 與 這兩個功能。(不用實作 )
GoFast 系統設計(面試官:Kilik)#
車輪戰第二輪是系統設計的題型,過程中有被要求錄影(可拒絕)以便面試官事後評選。
原始命題詳見下圖,需求是實作 GoFast 這個運輸產業的假想服務,討論範圍包含 Relational Database 的 Schama 設計,以及 API 的 High Level Design,設計出雛形之後會被要求追加需求,然後追問如何變更設計。


Functional Programming 題組(面試官:Rick)#
車輪戰第三輪考的是 Functional Programming,然後偷渡一些 Map-Reduce 的應用。整體實作上非常容易,但是題組每前進一題時,都會要求向下相容,個人覺得算是十分貼近日常開發的考法。
完整題組依序如下:
-
平移
############### 平移 ###############誰:行銷同仁想要:分析一份數據集希望:你提供一個函式,可以平移調整數據集,使均值為零,再回傳結果-----------------------------------函式:- shift_avg輸入:- data (原始數據集)輸出:- 處理後數據集-----------------------------------* 原始數據集=> 平移調整到均值 = 0=> 回傳新數據集################################### -
過濾
############### 過濾 ###############誰:行銷同仁想要:分析一份數據集希望:你提供一個函式,可以過濾出指定數值區間裡的數值,再回傳結果-----------------------------------函式:- filter_range輸入:- data (原始數據集)- start (過濾數值區間起始值)- end (過濾數值區間終止值)輸出:- 處理後數據集-----------------------------------* 原始數據集=> 過濾出指定數值區間裡的數據=> 回傳新數據集################################### -
版本 A
############## 版本 A ##############誰:行銷同仁想要:簡化多份數據集的分析過程希望:你提供一個函式,直接做完過濾、取樣、平移,再回傳結果-----------------------------------函式:- process輸入:- data (原始數據集)輸出:- 處理後數據集-----------------------------------Library- sample_by_num(data, N)取 1/N 做樣本-----------------------------------* 原始數據集=> 去掉所有負數=> 取 1/3 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集################################### -
版本 B
############## 版本 B ##############誰:行銷同仁想要:控制取樣與平移希望:- 擴充 process 函式,可以選擇是否要過濾負數- 向前相容 (版本 A)-----------------------------------函式:- process輸入:- data (原始數據集)- is_shift (控制是否要做平移調整)- is_filter (控制是否要做過濾)輸出:- 處理後數據集-----------------------------------* (過濾負數 & 做平移調整)=> 去掉所有負數=> 取 1/3 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集* (過濾負數 & 不做平移調整)=> 去掉所有負數=> 取 1/3 做樣本=> 回傳處理後數據集* (不做過濾負數 & 做平移調整)=> 取 1/3 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集* (不做過濾負數 & 不做平移調整)=> 取 1/3 做樣本=> 回傳處理後數據集################################### -
版本 C
############## 版本 C ##############誰:行銷同仁想要:觀察不同過濾方式的差異希望:- 擴充 process 函式,可以選擇過濾指定數值區間- 向前相容 (版本 B)-----------------------------------函式:- process輸入:- data (原始數據集)- is_shift (控制是否要做平移調整)- is_filter (控制是否要做過濾)- ...輸出:- 處理後數據集-----------------------------------* (過濾負數)=> 去掉所有負數=> 取 1/3 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集* (不做過濾負數)=> 取 1/3 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集* (過濾指定數值區間)=> 過濾出指定數值區間裡的數據=> 取 1/3 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集################################### -
版本 D
############## 版本 D ##############誰:行銷同仁想要:觀察不同處理流程的差異希望:- 擴充 process 函式,可以自由選擇下列處理方式- 向前相容 (版本 C)-----------------------------------* (處理 1)=> 過濾出指定數值區間裡的數據=> 取 1/3 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集* (處理 2)=> 取 1/4 做樣本=> 平移調整到均值 = 0=> 過濾出指定數值區間裡的數據=> 回傳處理後數據集* (處理 3)=> 平移調整到均值 = 0=> 去掉所有負數=> 取 1/2 做樣本=> 回傳處理後數據集* (處理 4)=> 平移調整到均值 = 0=> 取 1/6 做樣本=> 平移調整到均值 = 0=> 過濾出指定數值區間裡的數據=> 取 1/2 做樣本=> 平移調整到均值 = 0=> 回傳處理後數據集################################### -
版本 2
############## 版本 2 ##############誰:研發主管想要:減輕維護程式的負擔希望:你改良或重新設計程式的介面 or 架構- 可滿足行銷同仁先前提出的所有需求- 讓程式容易理解- 讓程式容易使用################################### -
版本 2-EX
############# 版本 2-EX ############誰:行銷同仁想要:有緩衝時間,來逐步將 process 替換為 (版本 2)希望:- 保留 process 的介面,直到替換完成- 你能提供 process 到 (版本 2) 的替換方式-----------------------------------誰:研發主管想要:減輕維護負擔,避免有兩份類似的處理邏輯希望:你改寫 process 內容,套用 (版本 2)###################################
神奇貨櫃平台(面試官:Rick)#
第三輪面試官似乎把題組用完了,所以搬出了 Bonus 題目,要求口述即可,題目細節如下圖:

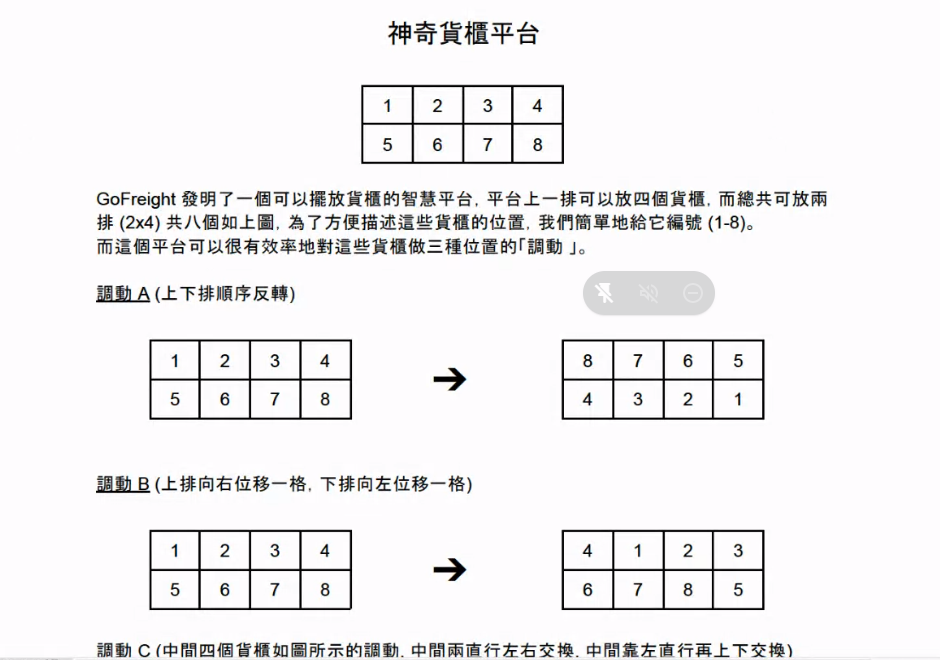
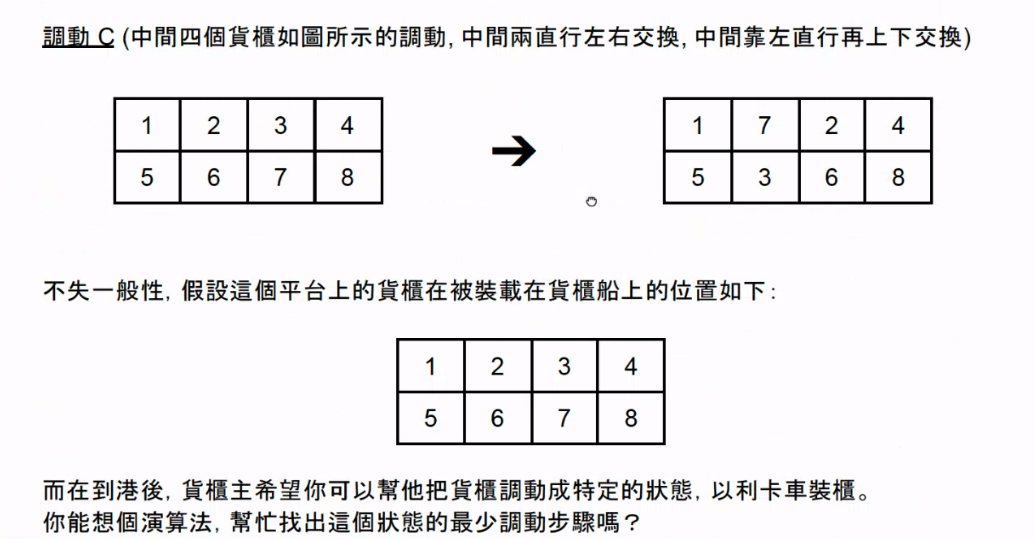
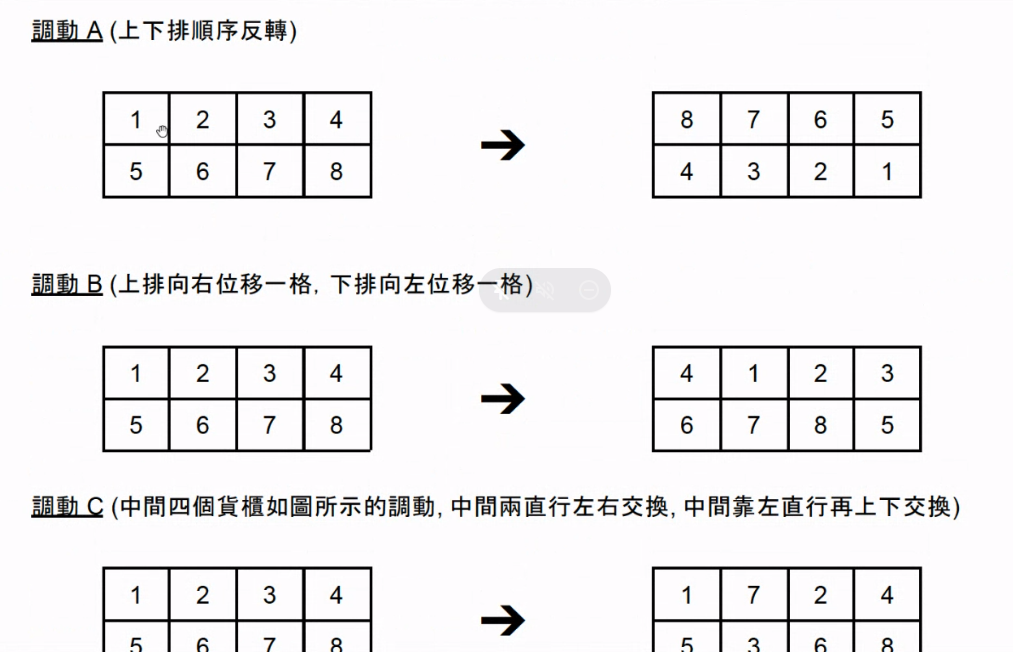
General Technical Questions(面試官:Falldog)#
車輪戰第四輪與 CTO 正面對決,直接各種口頭問答:
- Python 語言特性
- 與 的差異?
- 與 的差異?
- 是如何實作的?
- 有研究過 Garbage Collection 嗎?
- Process 與 Thread 的差異?寫過 Multi-Thread 程式嗎?用在哪裡?
- Unicode 與 UTF-8 的差異?1
- 解釋 Isolation Level
- Cookie 與 Session 的差異?
- 請盡可能詳細地描述在瀏覽器輸入某個網址後,直到看見畫面的過程
- 說明 2~3 個你曾經解決過的難題
面試結果及時程#
- 2021/08/26 投履歷
- 2021/08/27 收到測驗邀請
- 2021/08/29 第一輪線上技術測驗
- 2021/09/10 第二輪線上技術測驗(參與人:Gary、Kilik、Rick、Falldog)
- 2021/09/16 感謝信
附錄:第一輪線上技術測驗題目參考解答#
1. Balancing Parentheses#
本命題與 LeetCode 921. Minimum Add to Make Parentheses Validopen_in_new 相同。
以下解法為面試當下所寫,並非最優解。
def getMin(s): counter = 0 stack = [] for c in s: if c == '(': stack.append(c) counter += 1 elif c == ')': if len(stack) > 0: stack.pop() counter -= 1 else: counter += 1 return abs(counter)2. No Pairs Allowed#

def minimalOperations(words):
def min_substi(word): n = len(word) if n <= 1: return 0 i = 0 j = 1 ans = 0 while j < n: if word[i] == word[j]: j += 1 else: # increment ans length = j - (i + 1) + 1 ans += length // 2
# iterate i = j j = i + 1
# increment ans length = j - (i + 1) + 1 ans += length // 2
return ans
return [min_substi(word) for word in words]3. Fun with Anagrams#

def funWithAnagrams(text): patterns = set() answers = []
def string_to_pattern(s): count_map = {} for c in s: if c not in count_map: count_map[c] = 0 count_map[c] += 1 sorted_letters = sorted(count_map.keys()) pattern = ''.join([f'{c}{count_map[c]}' for c in sorted_letters]) return pattern
for string in text: pattern = string_to_pattern(string) if pattern not in patterns: patterns.add(pattern) answers.append(string) return sorted(answers)4. Counting Pairs#

def countPairs(numbers, k): n = len(numbers) numbers_set = set(numbers) pairs = set() for a in numbers: b = a + k if b in numbers_set: pairs.add((a, b)) return len(pairs)5. Scatter-Palindrome#

面試當下未能寫出,以下解答是測驗結束後筆者參考網路資源2後重新撰寫。
def get_scatter_palindrome_count(s): ans = 0 n = len(s) for i in range(n): alphabet_count_map = {} for j in range(i, n): alphabet = s[j] if alphabet not in alphabet_count_map: alphabet_count_map[alphabet] = 0 alphabet_count_map[alphabet] = (alphabet_count_map[alphabet] + 1) % 2
s_size = j - i + 1 if s_size % 2 == 0: if all([v == 0 for v in alphabet_count_map.values()]): ans += 1 print(s[i:j + 1]) elif s_size % 2 == 1: if len([None for v in alphabet_count_map.values() if v == 1]) == 1: ans += 1 print(s[i:j + 1]) return ans
def scatterPalindrome(strToEvaluate): return [get_scatter_palindrome_count(s) for s in strToEvaluate]第二輪線上技術測驗題目參考解答#
實作 Heap#
當場 Google 到這篇教學: https://codelearner.pixnet.net/blog/post/131124376open_in_new
"""[9,8,7,6,5] 0 1 2 3 4
9 / \ 8 7 / \6 5"""
class MaxHeap:
def __init__(self, max_size): self._max_size = max_size self._next = 0 # 下一個可以填的位置 self._data = [None for _ in range(max_size)]
def push(self, value): if self._next == self._max_size: raise Exception('heap is full') self._data[self._next] = value self._next += 1
current_index = self._next - 1 while self._data[current_index] > self._data[(current_index - 1) // 2]: self._data[current_index], self._data[(current_index - 1) // 2] = self._data[(current_index - 1) // 2], self._data[current_index] current_index = (current_index - 1) // 2
def pop(self): if self._next == 0: raise Exception('heap is empty') top = self._data[0] self._next -= 1 self._data[0] = self._data[self._next] self._data[self._next] = None current_index = 0 while True: left_index = current_index * 2 + 1 right_index = current_index * 2 + 2
if left_index < self._next: left_value = self._data[left_index] else: left_value = -float('inf')
if right_index < self._next: right_value = self._data[right_index] else: right_value = -float('inf')
if not (self._data[current_index] < max(self._data[left_index], self._data[right_index]): break
if left_value >= right_value: self._data[left_index], self._data[current_index] = self._data[current_index], self._data[left_index] current_index = left_index elif right_value > left_value: self._data[right_value], self._data[current_index] = self._data[current_index], self._data[right_value] current_index = rightt_index
return topGoFast 系統設計#
-
Schema 設計
class Product:id = Column(pk=True, index=True)class User:id = Column(pk=True, index=True)class Payment:id = Column(pk=True, index=True)create_time = Column(DateTime)class Quotation:id = Column(pk=True, index=True)class Order:id = Column(pk=True, index=True)quotation_id = Column(ForeignKey('quotation.id'))quotation = relationship(quotation_id)product_id = Column(ForeignKey('product.id'))product = relationship(product_id)user_id = Column(ForeignKey('user.id'))user = relationship(product_id, backref='orders')payment_id = Column(ForeignKey('payment.id'))payment = relationship(product_id)desination = Column(String)state = Column(Enum)class OrderDelivery:id = Column(pk=True, index=True)order_id = Column(ForeignKey('order.id'))order = relationship(order_id)tracking_reference = Column(String)def deliver(self):raise NotImplementedErrordef sync(self):raise NotImplementedErrorclass 廠商AOrderDelivery(OrderDelivery):def deliver(self):# call apiself.tracking_reference = tracking_referencedef sync(self):# call apipassclass 廠商BOrderDelivery(OrderDelivery):...class WMSAPIClient:def get_product(self, product_id):passdef create_shipment_order(self, payload):passdef get_shipment_order(self, shipment_order_id):passclass OrderDeliveryItem:id = Column(pk=True, index=True)order_delivery_id = Column(ForeignKey('order_delivery.id'))order_delivery = relationship(order_delivery_id)location = Column(String) -
API 設計
def get_unique_products():user = session.query(User).filter(User.id == 'A').one() # 1 requestorders = user.orders # 1 requestunique_product_ids = set([order.product_id for order in orders]) # 0 request# 訂購POST /quotations # also create payments{orders: [{destination: ...},{destination: ...},]}# 付款POST /quotations/:id/pay{payment_card_id: ...}# 取消POST /quotations/:id/cancelPOST /orders/:id/cancel# 出貨 (internal)POST /orders/:id/deliverdef deliver():client = WMSAPIClient()client.get_product()if 庫存足夠:order.order_delivery.deliver() -
排程設計
@BatchJob(hours=1)def sync_庫存():orders = ...for order in orders:order.order_delivery.sync() -
Follow up
實作完上面題目後繼續被問到:跨越兩個地理位置相隔遙遠的倉儲系統,要如何讓終端使用者知道某商品的庫存總數?
當下的回答是:可以使用獨立的 cache service 維護一個 lookup table,key-value 如下所示
counting_map = {<product_id>: 兩個倉儲加總數量}
Functional Programming 題組#
-
平移
def shift_avg(data):count = len(data)if count == 0:return []total = sum(data)avg = total / countreturn [item - avg for item in data] -
過濾
def filter_range(data, start=None, end=None):if start is None:start = -float('inf')if end is None:end = float('inf')return [item for item in data if start <= item <= end] -
版本 A
def process(data):data = filter_range(data, start=0, end=None)data = sample_by_num(data, 3)data = shift_avg(data)return data -
版本 B
def process(data, is_shift=True, is_filter=True):if is_filter:data = filter_range(data, start=0, end=None)data = sample_by_num(data, 3)if is_shift:data = shift_avg(data)return data -
版本 C
class FilterArgs:def __init__(self, start, end):self.start = startself.end = enddefault_filter_args = FilterArgs(start=0, end=None)def process(data, is_shift=True, is_filter=True, filter_args=default_filter_args):if is_filter:data = filter_range(data, start=filter_args.start, end=filter_args.end)data = sample_by_num(data, 3)if is_shift:data = shift_avg(data)return data -
版本 D
class Operator:passclass SamplingOperator:def __init__(n):passdef process(..., operations=List[OperationEnum])passprocess(..., [SamplingOperator(3), ...])process(..., [SamplingOperator(5)]) -
版本 2
class AbstractOperator:def operate(self, data):raise NotImplementedErrorclass SamplingOperator(AbstractOperator):def __init__(self, n):self._n = ndef operate(self, data):return sample_by_num(data, self._n)class ShitToZeroOperator(AbstractOperator):def operate(self, data):return shift_avg(data)class FilterRangeOperator(AbstractOperator):def __init__(self, start, end):self._start = startself._end = enddef operate(self, data):return filter_range(data, start=self._start, end=self._end)def process_v2(data, operations: List[Operator]):for operator in operators:data = operator.operate(data)return dataprocess_v2(data, [SamplingOperator(3), ShitToZeroOperator()])process_v2(data, [ShitToZeroOperator(), SamplingOperator(3), FilterRangeOperator(1, 5)]) -
版本 2-EX
def process(data, is_shift=True, is_filter=True, filter_args=default_filter_args):if is_filter:data = FilterRangeOperator(start=filter_args.start, end=filter_args.end).operate(data)data = SamplingOperator(3).operate(data)if is_shift:data = ShitToZeroOperator().operate(data)return data
神奇貨櫃平台#
此題直覺解法為建立一顆狀態樹,以初始狀態做為根結點,每種貨櫃的調動方式都向下展開一顆獨立的子樹,最後以 BFS 走訪所有節點比對是否為目標狀態即可得到最短調動次數及路徑。如果要改善此策略,可以預先計算 A、B、C 三種調動方式執行幾次後會循環(例如 A 調動每 2 次會回到原始狀態),接著便能利用此特性替狀態樹剪枝。
此題與 Leetcode 752. Open the Lockopen_in_new 解法相似。
註釋#
-
GoFreight 編碼爭議事件
在筆者參與面試前約兩周,GoFreight 曾在 PTT Soft_Job 板張貼徵才文open_in_new,因鄉民在該文章下方推文熱議 Unicode 與 UTF-8 相關的編碼問題,導致筆者在面試當下無法判斷此題是純技術問題還是政治問題,望讀者留意。 ↩
-
return count of scatter palindrome of a string [closed]open_in_new ↩